
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- hyperledger
- smart cast
- 티스토리
- jsp
- auto configure
- 문법 정리
- 알고리즘
- 자바 프로젝트
- 운영체제
- K6
- resilience4j
- MongoDB
- 자바
- 학점
- c#
- 리눅스
- 유사코드
- 초대장
- oracle
- SQL
- spring
- gradle
- 백준 알고리즘
- 파이썬
- 파이썬 소스
- dynamic query
- JVM
- 프로젝트
- 오라클 디비
- 오라클
- Today
- Total
목록목차 (231)
모종닷컴
브로커와 컨트롤러 카프카 버전 2.8 이후부터 메타데이터 관리를 주키퍼를 사용하지 않고 자체 관리하게 되었는데 이로 인해 카프카 애플리케이션의 역할은 크게 두 가지(브로커, 컨트롤러)로 구분할 수 있다. '컨트롤러'는 클러스터 수준의 메타데이터 관리 및, 리더 선출, 브로커 추가 제거 같은 클러스터 관리 작업을 하는 역할을 하며, '브로커'는 메시지의 저장 및 전송과 관련된 작업을 담당한다. 애플리케이션을 역할을 지정할 수 있는데, 브로커나 컨트롤러 중 하나의 역할만 지정할수도 있고, 브로커 겸 컨트롤러 역할도 지정할 수 있다. Quorum based Controller KRaft 합의 알고리즘을 통해 리더로 선출된 컨트롤러는 Active Controller라고 불리며, 그 외에 컨트롤러는 Followe..
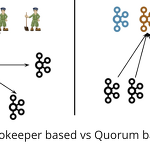 KRaft 합의 알고리즘
KRaft 합의 알고리즘
zookeeper를 이용한 카프카 메타데이터 관리 카프카 2.8 버전 이전에는 아래와 같은 메타데이터들을 관리하기 위해 zookeeper를 사용했었음. 클러스터 토폴로지 정보, 토픽 메타데이터, 컨트롤러 정보, 컨슈머 그룹 정보, ACLs 정보, 브로커 정보 등.. Zookeeper를 통해 메타데이터를 관리했을 떄 발생하는 문제들 Zookeeper 자체에 이슈가 있다기보다는 주키퍼를 활용하여 메타데이터를 관리하는 카프카의 방식에 여러 가지 문제가 있었음. 주키퍼라서 생기는 문제들. 주키퍼는 카프카와 별개의 분산 시스템 관리자는 카프카를 배포하기 위해 두 개의 개별 분산 시스템을 관리하고 배포하는 방법을 배워야 한다. SASL과 같은 설정이 카프카, 주키퍼 두 시스템에 모두 적용되어야 한다. 로컬에서 간단..
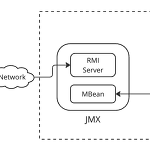 카프카 모니터링 - 메트릭
카프카 모니터링 - 메트릭
카프카 메트릭카프카 코드를 보다 보면 메트릭을 수집해서 특정 클래스에서 계속 계산하는 모습을 볼 수 있습니다. 해당 클래스들은 MBean을 상속받아 작성되어 있어서 내부 메트릭을 JMX를 통해 얻을 수 있습니다. 브로커 뿐만 아니라 KRaft 같은 메타데이터, Producer, Consumer 등의 메트릭도 모두 JMX를 이용할 수 있습니다. 다만 메트릭에 접근하기 위해서는 몇 가지 설정이 필요합니다.Java Management Extensions (JMX)는 Java 애플리케이션을 모니터링하고 관리하기 위한 기술. JMX는 MBean (Managed Bean)이라는 관리 가능한 자바 오브젝트를 사용하는데 애플리케이션은 이 MBean을 통해 다양한 정보와 작동 상태를 노출하며, 관리자 또는 모니터링 도구..
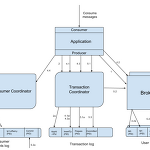 Kafka Transaction
Kafka Transaction
Transaction 카프카 트랜잭션은 주로 비동기 데이터 스트림에서 읽고 쓰는 패턴을 가진 애플리케이션을 위해 설계되었다. 초기에는 스트림 처리 애플리케이션이 부정확한 처리를 허용했음. (웹 페이지 조회수, 좋아요 수) 그러나 카프카에 대한 인기가 증가하면서 정확한 처리에 대한 요구사항들이 생김(인출, 입금 등) idempotent Producer는 다중 파티션에 대한 보증은 할 수 없다. Transactional Semantics Atomic multi-partition writes 트랜잭션은 다수의 토픽과 파티션에 대한 원자적인 쓰기를 가능하게 한다 트랜잭션에 포함된 메시지들은 전체 성공하거나 아니거나 둘 중에 하나 Zombie fencing 최초 프로듀서가 시작할 때 카프카 클러스터에 transa..
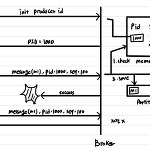 Exactly Once Semantics
Exactly Once Semantics
Kafka Producer를 한 번이라도 봤다면 Acks 및 retry 관련 설정을 본 적이 있을 겁니다. 이와 관련돼서 항상 등장하는 단어 중 하나는 Exactly One Semantics입니다. Exactly One Semantics는 정확히 한 번만 레코드를 저장한다입니다. Acks, Retry 설정을 조정해 보면서 이 Exactly Once Semantics가 왜 필요한 건지 알아보도록 하겠습니다. Acks, Retry 설정을 통해 메시지를 전달하는 방식에는 크게 3가지로 분류됩니다. At Most Once, At Least Once, Exactly Once입니다. At Most Once Delivery Semantics 최대 한 번만 전송 시도를 하는 방식입니다. Retry 설정을 0, Acks..
요즘 카프카에 푹 빠져서 살고 있습니다. 기존에는 카프카의 메타데이터 관리를 위해 Zookeeper를 사용하고 있었는데, 2.8.0 버전부터는 주키퍼에서 카프카 자체적으로 메타데이터를 관리하기 위해 Self-Managed Metadata Quorum이 추가되었습니다. 카프카 문서 KIP-500에는 주키퍼에서 새로운 Self-Managed Quorum 방식으로 전환하기 위해 Rolling Upgrade 라는 설명을 하고 있습니다. "Rolling Upgrade"라는 것은 소프트웨어의 새로운 버전을 서비스 중단 없이 순차적으로 업그레이드 할 수 있도록 지원하기 위한 방법을 말합니다. 저희도 개발하다보면 위와 같은 상황이 올 수 있습니다. 예를 들어 통신 중인 A,B 서버의 API 스펙이 변경될 때가 있는데,..
 카프카 책 추천
카프카 책 추천
최근 카프카를 배우기 위해 책을 읽고 있는데 정말 좋았다 싶은 책들이 있어 추천드리려고 합니다. 총 2권의 책을 추천드리려고 하는데 하나는 "카프카, 데이터 플랫폼의 최강자"와 다른 하나는 "카프카 핵심가이드"입니다. 순서는 "카프카, 데이터 플랫폼의 최강자"를 먼저 읽고 나서 "카프카 핵심가이드" 책을 읽는 게 좋은 것 같습니다. 카프카, 데이터 플랫폼의 최강자 어떤 기술을 배울때 저는 아래 순서로 스터디를 하기 위해 노력합니다. 이 기술은 무엇인가? 이 기술을 사용해야 하는 이유가 무엇인가? 기술의 핵심 원리 이것을 사용하기 위한 방법 기술 응용 단순히 기술을 사용하는 방법을 익히기보다는 기술의 탄생 배경이나 핵심 원리에 관한 지식이 기반이 된 상태로 시작해야 응용 및 운영하기도 편하고 사용할 때에도..
디버깅을 하면서 주석을 열심히 읽고 있는데 익숙한 단어가 보이네요. 익숙하긴 한데 솔직히 기억은 안납니다. Reentrancy Reentrancy는 재진입성이라는 뜻을 가지고 있습니다. 주로 프로그래밍에서 자주 언급이 되는데, 가끔 시스템 디자인 쪽에서도 언급이 되는걸 본적이 있던것 같습니다. 찾아보면 뭐 여러가지 다양한 해석들이 많은데 결국 핵심은 병렬 실행이 가능한 환경에서 안전하게 실행 가능한 함수를 뜻하는 거라고 생각됩니다. 병렬 실행에서 안전하게 실행 가능하기 위해서 몇 가지 조건이 필요할텐데 위키백과에서는 그 특징 몇 개를 이렇게 나열하고 있습니다. 전역 변수를 사용하지 않는다 전역 변수의 주소를 반환하지 않는다 호출자가 제공한 매개변수만으로도 동작해야 한다 싱글턴 객체의 잠금에 의존하지 않는..
 Kotlin Contract
Kotlin Contract
요즘 Coroutine을 학습 중에 있습니다. 좀 Deep dive를 하자는 의미에서 디버깅을 시작하는데 시작하자마자 턱 막혀버렸습니다. 오늘의 주인공 contract입니다. Coroutine에서 만든 API인 줄 처음에 착각했는데 막상 보니 코틀린 표준 라이브러리에 들어가 있는 친구였습니다. Kotlin Contract Kotlin 1.3 이후부터 지원하기 시작한 실험적인 API 코틀린 컴파일러에게 함수의 동작을 명시적으로 설명해주는 것 Kotlin Compiler 코틀린으로 작성된 소스 코드를 JVM이 이해할 수 있는 바이트코드(.class 파일)로 변환하는 일을 담당 저희가 작성한 코드를 정적 분석을 통해 바이트코드로 전환할 때 유용한 기능들이 있는데 그중 하나가 스마트 캐스트입니다 스마트 캐스트 ..
 [k6] Visualization
[k6] Visualization
k6 결과 매트릭을 외부로 보낼 수 있습니다. Json 파일로 결과 저장 테스트할 때 사용할 스크립트는 아래와 같습니다. import http from 'k6/http'; import { check, sleep } from 'k6'; export const options = { stages: [ { duration: '3s', target: 20 }, { duration: '10s', target: 10 }, { duration: '7s', target: 0 }, ], }; export default function () { const res = http.get('https://httpbin.test.k6.io/'); check(res, { 'status was 200': (r) => r.status =..